Analyse des notes du DNB¶
En bon prof de math, on commence par un petit cours sur les boites à moustaches! C'est un super outils pour visualiser la répartition des données entre elles.
On sépare les données en 4 groupes de même taille (25%). Un groupe dans une moustache, un dans une partie du corps, un dans l'autre partie du corps et le dernier dans l'autre moustache.
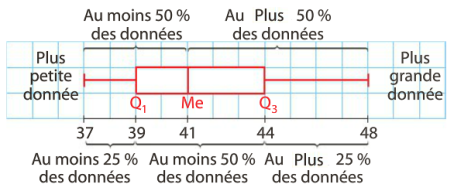
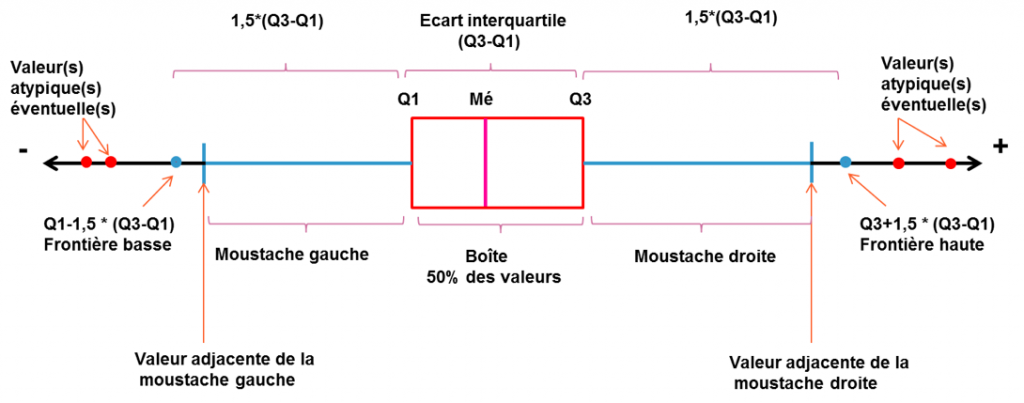
Je laisse ceux qui ne sont pas partis en courant à appuyer sur la flèche du bas ou espace pour avoir une boite à moustache un peu plus complexe et complete.
Pour les autres c'est flèche de gauche.
DNB Général¶
Ici juqu'au contraire, on ne parlera que des classes qui ont passé le DNB générale.
gene
Les absents ont toujours tord. On les sort de toute l'analyse qui suiva.
absents = df[df.isnull().any(1)]
absents[["Classe", "Nom"]+matieres]
Répartition des notes.¶
Le DNB blanc était noté sur 325.
df["total"].hist(bins=150, figsize=(15, 5))

Quelques statistiques!¶
Pour les non anglophones mean signifie moyenne, std (standart deviation) signifie écart type
Barèmes: Français 100 HG 50 Math 100 SVT 25 Physique Chimie 25 Techno 25
round(df[matieres].describe(), 2)
Répartition des notes par matières¶
Vous allez enfin retrouver les boites à moustaches!
Les notes ont été normalisées pour pouvoir comparer les épreuves
df[norm_matieres].boxplot(figsize=(15,5))

Les plus motivés pourront faire flèche du bas pour voir pleins de beaux graphiques qui ne disent pas grand chose (mais j'aime qu'on me fasse mentir).
Y a-t-il un lien entre la réussite dans une matière et dans une autre?¶
Dans les nuages de points, chaque point correspond à une élèves.
On compage ses notes dans deux matières à chaque fois. L'idée est de voir si la réussite dans une matière est liée à la réussite dans une autre (elles sont corrélées) ou si au contraire, il n'y a pas de lien. Elles sont fortement corrélées quand les points sont regroupés. Si les points sont éclatés, la réussite dans une matière ne semble pas de rapport avec la réussite dans une autre.
Les graphiques du milieu montre la répartition de toutes les notes dans chaque matière.
ax = scatter_matrix(df[matieres],
alpha=0.5,
figsize=(15, 15),
#diagonal='kde',
)

Une autre version mais chaque couleur correspond à une classe.
fig = sns.pairplot(df,
vars=norm_matieres,
hue="Classe",
diag_kind="kde",
plot_kws={'alpha':0.5,},
)

Comparaison des classes entre elles¶
Parce que chaque prof principale aime que sa classe soit la meilleure!
Mais rappelez vous, la comparaison des classes entre elle n'a pas beaucoup d'interet pour juger les élèves. Chaque classe n'a pas été corrigée par le même correcteur et on sait tous à quel point les autres profs sont pas sympas avec nos classes!

Score total¶
bp_data.plot(title="Total de points",
kind="box",
grid=True,
figsize=(15,5))

Français¶
df[["Français", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Histoire géo¶
df[["HG", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Les maths¶
df[["Maths", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

SVT¶
df[["SVT", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Physique¶
df[["Physique", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Techno¶
df[["Techno", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

DNB pro¶
On ne parle plus que des DNB pro maintenant
pro
Elèves absent à au moins une epreuve
absents = df[df.isnull().any(1)]
absents[["Nom", "Classe"]+matieres]
Répartition des notes¶
df["total"].hist(bins=150, figsize=(15, 5))

Statistiques par matières et le total¶
round(df[matieres+["total"]].describe(), 2)
Données par matières¶
On a rapporté les notes sur 1 pour pouvoir comparer les matières entre elles.
df[norm_matieres].boxplot(figsize=(15,5))

Y a-t-il un lien entre la réussite dans une matière et dans une autre?¶
ax = scatter_matrix(df[matieres],
alpha=0.5,
figsize=(15, 15),
diagonal='kde')

fig = sns.pairplot(df,
vars=norm_matieres,
hue="Classe",
diag_kind="kde",
plot_kws={'alpha':0.5,},
)

Le total des points¶
bp_data.plot(title="Total de points",
kind="box",
grid=True,
figsize=(15,5))

Français¶
df[["Français", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Histoire géo¶
df[["HG", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Les maths¶
df[["Maths", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

SVT¶
df[["SVT", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Physique¶
df[["Physique", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))

Techno¶
df[["Techno", "Classe"]].set_index("Classe", append=True).unstack(1).boxplot(figsize=(15, 5))
